
bupaR 0.5.0: What’s new?
We are happy to share with you a new release of bupaR, edeaR and processmapR. Next to many bugfixes and performance improvements, this release contains 3 major functional updates.
- Introduction of the activitylog object class, allowing for more concise datasets and improved performance during analysis.
- A new framework for adding calculated variables to your log.
- Improved data manipulation using dplyr verbs.
Activitylog
As of this release, bupaR supports two different kinds of log formats:
- eventlog: data set in which each row represents a single event. This means that it has a single timestamp.
- activitylog: data set in which each row represents a single activity instances. This means it can has multiple timestamps, stored in different columns.
The illustration below shows the difference between the two. The new activitylog object has the advantages that it will typically require less memory, and allows for faster analysis, since correlation of events to activity instances is built-in. The eventlog on the other hand provides much more flexibility, as events with the same lifecycle can be repeated within an activity instance (which might be the case for suspend and resume events). Furthermore, it allows attribute values to be stored at the event level, so that events of the same activity instance can have different values.
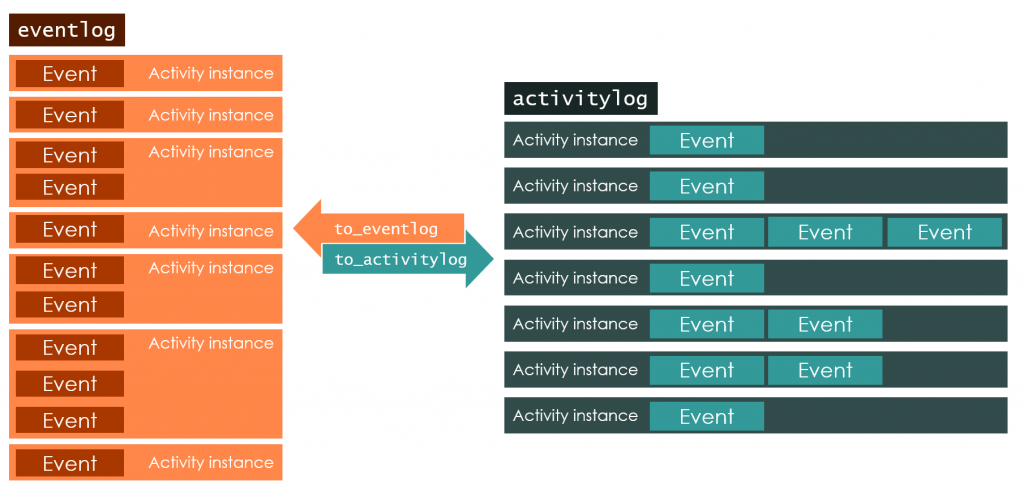
Functions in bupaR, edeaR and processmapR are currently supported for activitylog objects. Other packages will follow in the future, while the to_eventlog and to_activitylog functions can be used to transform one into another if needed.
Augmenting Your Log
For all descriptive metrics in edeaR the append arguments are deprecated in favour of the new augment function. The augment function can take any descriptive metric and join (a selection of) columns to the original log. This makes it easy to add calculated attributes to your log for further analysis.

For example, we can take the sepsis log, compute the throughput times of each case, and add this information as a new variable to the sepsis log, where we can then use it for further analyses.
sepsis %>%
throughput_time("case") %>%
augment(sepsis)This new workflow for enriching logs makes sure that all metric functions will consistently return logs in the future. Compared to the deprecated approach using append arguments, the new augment function furthermore provides a standardized and transparant way to manage the data enrichment, using the arguments columns to specify which columns should be added, and prefix to specify a prefix that should be added to the names of these columns. The augment function works for all metrics in edeaR, all analysis levels, and for both activitylog and eventlog objects.
Improved Data Manipulation
Included in this release are important changes to the dplyr verbs that bupaR supports, most significantly group_by. These verbs can be used for event data manipulation as well as for descriptive analytics that goes beyond the built-in levels of many of the available metrics.
For example the code below identifies the last activity in each case, adds this information to the log with prefix “end”, and then computes the distribution of throughput time for each group defined by the information. The resulting plot shows the distribution of throughput time for each end activity.
sepsis %>%
end_activities("case") %>%
augment(sepsis, prefix = "end") %>%
group_by(end_activity) %>%
throughput_time() %>%
plot()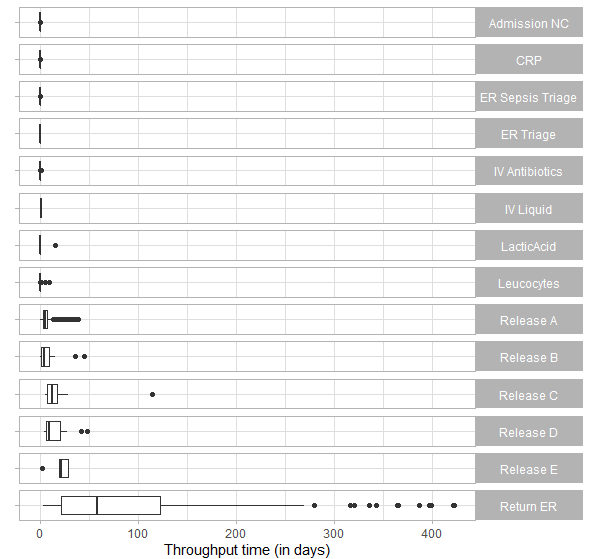
As of this release, the grouping mechanism of logs is improved and more widely available. Furthermore, grouping can now also be done on identifiers of the log in question. The following code will compute in how many cases an activity is executed.
sepsis %>% group_by(activity) %>% n_cases()Grouping on log identifiers is even made more easy with the group_by_ids function, where you can specificy a list of identifiers, instead of column names.
sepsis %>% group_by_ids(activity_id, resource_id)The new versions of bupaR, edeaR and processmapR are available on CRAN and GitHub.
Upcoming webinar
Interested to discover the latest functionality in more depth? Register for the upcoming tutorial on Advanced Event Data Wrangling with bupaR 0.5.0, organized by the Business Informatics Research group at Hasselt University.